[sept. 8th, 21:22: fixed a +/- 1 error]
In a previous post, I gave a high-level description of
how Clojure's PersistentVector is implemented. While the code has changed, the description was high-level enough that the explanations still hold (although some code snipplets don't correspond to what's in
Git master.)
In this post, I'll try to explain (also at a high level) how
clojure.lang.PersistentHashMap works internally. Reading the mentioned post on PersistentVector is helpful as some of the concepts are the same (e.g., bit-partitioning).
Persistent
PersistentHashMap is a persistent version of the classical hash table data structure. Persistent means that the data structure is immutable, yet has efficient non-destructive operations that correspond to the operations on the classical hash table. E.g., put(K,V) in hash table corresponds to a side-effect free function assoc(P, K, V) which computes from P a new PersistentHashMap P' which is like P except that it maps key K to value V. The word "efficient" means "on par" with their mutating counterparts. For Clojure data structures, Rich tries to make them within 1-4 of the Java data structure operations; and read-only operations can even be faster than Java's. Later I will cover 'transients' which are a new optimization that make "batch" operations faster.
Array-mapped hash trie
In his paper
Ideal Hash Tries Phil Bagwell describes a data structure "Hash Array Mapped Trie" which is an efficient implementation of a Hash Tree, based on a combination of hashing and the
trie data structure. Hash Array Mapped Tries, are not persistent or immutable. What Rich did was create a persistent version of Bagwell's data structure;
clojure.lang.PersistentHashMap.
PersistentHashMap basic idea
PersistentHashMap (PHM) maintains a very-wide tree, each node having up to 32 children. Each node is a concrete implementation of a static inner interface,
INode, and there are five implementations of this interface: EmptyNode, LeafNode, FullNode, HashCollisionNode, BitmapIndexedNode. I'll only cover EmptyNode, LeafNode and BitmapIndexedNode; the latter being where most of the interesting stuff happens.
The
INode interface look like this:
static interface INode{
INode assoc(int shift, int hash, Object key, Object val, Box addedLeaf);
LeafNode find(int hash, Object key);
}
The
assoc method "adds" a new key-value pair to the map. The
find method searches for the Leaf-node holding a key.
An EmptyNode simply represents the empty hash map. LeafNodes are also pretty simple; they hold the actual entries stored in map.
The root node of the tree is initially an EmptyNode. When assoc is called on EmptyNode, it returns a new LeafNode, which the key-value pair. So EmptyNode "becomes" a LeafNode with assoc. In turn, a LeafNode typically "becomes" a BitmapIndexedNode with assoc. We will go into details with BitmapIndexedNode, but first we need to understand...
Bit-partitioning of hash-codes
When PHM assocs a key object K with value object V, it first computes the hashCode of K, just as a hash-table would. The hash code of K yields an int, which has a 32-bit representation in Java (as I explained in
the post on PersistentVector). Here are some example bit representations of numbers:

The trick that PHM uses is to partition this bit representation in to blocks of 5-bits, represented with colors in the above example. Each block corresponds to a "level" in the tree structure; for example, the right-most green block corresponds to root-level, and the orange block corresponds to the children of the root. Exactly what "corresponds" means is described below. Levels are multiples of 5. I.e., the root level is level 0, the children of the root are level 5, the grand-children of the root are level 10, etc. Note that a block of five bits corresponds to a number in the range 0-31.
The reason that levels are multiples of five is the following: You have a bit-representation of a hash-code and you are interested in a particular block corresponding to a level
n. You obtain this number in two steps: first move the block of bits to the right, until it is the right-most block. Then null-out all other bits except this right-most block. The is done with two bit-operations: you simply right-shift the bits with the level
n and then do a bit-wise 'and' (
&) with the pattern
00..11111. For example, suppose you want the block corresponding to level 5 (the orange block) of the number 1258 (binary:
[00001][00111][01010]). You right shift with the level, 5, which is
[00000][00001][00111]; then do the null'ing, yielding
[00111], which was exactly the orange block of 1258.
The following function does this.
static int mask(int hash, int shift){
return (hash >>> shift) & 0x01f;
}
Illustrating the tree structure
I'll use the following picture (adapted from one of Rich's slides).
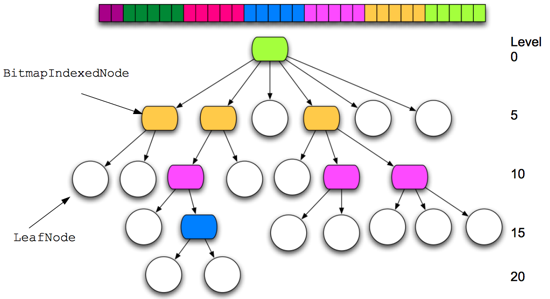
The colored nodes are
BitmapIndexedNodes and have between 2 and 31 children (should they get a 32nd child, they become
FullNodes). A naive implementation of
BitmapIndexedNode might be the following: use an int variable,
level, to denote the level that this node lives in, and allocate a full 32 element array of INode references for the children. To add a new child: lookup the index via the bit-block corresponding to the level, i.e. given a hashCode
hash for the child, and given the level, call
mask(hash, level) to get the index in range [0, 31]. But this strategy wastes a lot of memory: each node has a full 32 element array where most entries are simply
null, i.e., if there are 4 children there are 28 null references which are just wasting space.
The hard part is to only use as much space as is needed for each
BitmapIndexedNode, i.e., if a
BitmapIndexedNode has
N children it maintains an array of size
N. But then we can't use
mask(hash,shift) as the index into the array since it returns a number in the range [0,31] and we need a number only in range [0,
N).
bitpos
So we need a function to map numbers in range [0, 31] to indexes in range [0,
N). The function has to be fast constant time, since we are using it to find the child of a node from a hash code, which we will do at each level in the tree. The function is a composition of two functions:
bitpos and
index. Function
bitpos maps numbers [0, 31] to powers of two, i.e., numbers that have a binary representation of the form:
{10n | n >= 0}.
For example,
bitpos(7) in binary is 10000000. We always look at
bitpos(x) in binary form. Function
index we return to shortly.
static int bitpos(int hash, int shift){
return 1 << mask(hash, shift);
}
bitmap
Each
BitmapIndexedNode also maintains an int variable
bitmap which we also look at in binary form. The
bitmap tells us how many children this node has, and also what their indexes are in the child array. All this is encoded into one
int variable! How? The bit-map has a binary representation, e.g.,
00000000000000010000000010000101
The number of children is the number of
1's in the binary representation. If the
nth bit in
bitmap is
1 (counting right-to-left, starting with position 0) then there is a child with index
n. So to check if a child exists for a certain hash-code: first compute
mask(hash,shift) to get the bit-block and number in range [0, 31]. Then compute
bitpos of this. You then have a number of form
10n. Now match that with the
bitmap to check if there is a
1 in the
n'th position; this match is simply a bit-wise and, '&', with
bitpos. We'd better take an example.
Suppose we are at level 5, and looking up an element with hash-code 1258. Suppose also the bitmap-indexed node has four children, with
bitmap
bitmap =binary rep 00000000000000010000000010000101
Now check if there is a child for hashCode 1258 at this level:
mask(1258,5) = 7 (i.e., binary
00111 as we saw before).
bitpos(7) =binary rep 10000000
00000000000000010000000010000101 &
00000000000000000000000010000000 = 1
Which means that the child exists. Now what is its index? This is where the
index function comes into play...
index
This is the final piece of bit-trickery, I promise ;-) The index of a child is the number of
1's to the right of the child's
bitpos in the bit map. In our example above, the index corresponding to hash code 1258 would be 2, since there are two
1's to the right of
10000000 in the
bitmap. Now the trick is that on many processors there is an efficient instruction called CTPOP which counts the number of ones in the bit representation of an integer (CTPOP is "count (bit) population"). Note that if we subtract 1 from the bitpos,
10n, we get
01n, then binary 'and' with the bit map gives us the same bit map, but where only the
1's to the right of
bitpos are present. If we do a CTPOP on this, we get the index. Hence,
final int index(int bit){
return Integer.bitCount(bitmap & (bit - 1));
}
To be continued...
From this you should be able to understand how find works. In combines all this:
final static class BitmapIndexedNode implements INode{
final int bitmap;
final INode[] nodes;
final int shift;
static int bitpos(int hash, int shift){
return 1 << mask(hash, shift);
}
final int index(int bit){
return Integer.bitCount(bitmap & (bit - 1));
}
public LeafNode find(int hash, Object key){
int bit = bitpos(hash, shift);
if((bitmap & bit) != 0)
{
return nodes[index(bit)].find(hash, key);
}
else
return null;
}
}
In part 2 we look at how assoc works...